搜索到
111
篇与
哈根达斯
的结果
-

-
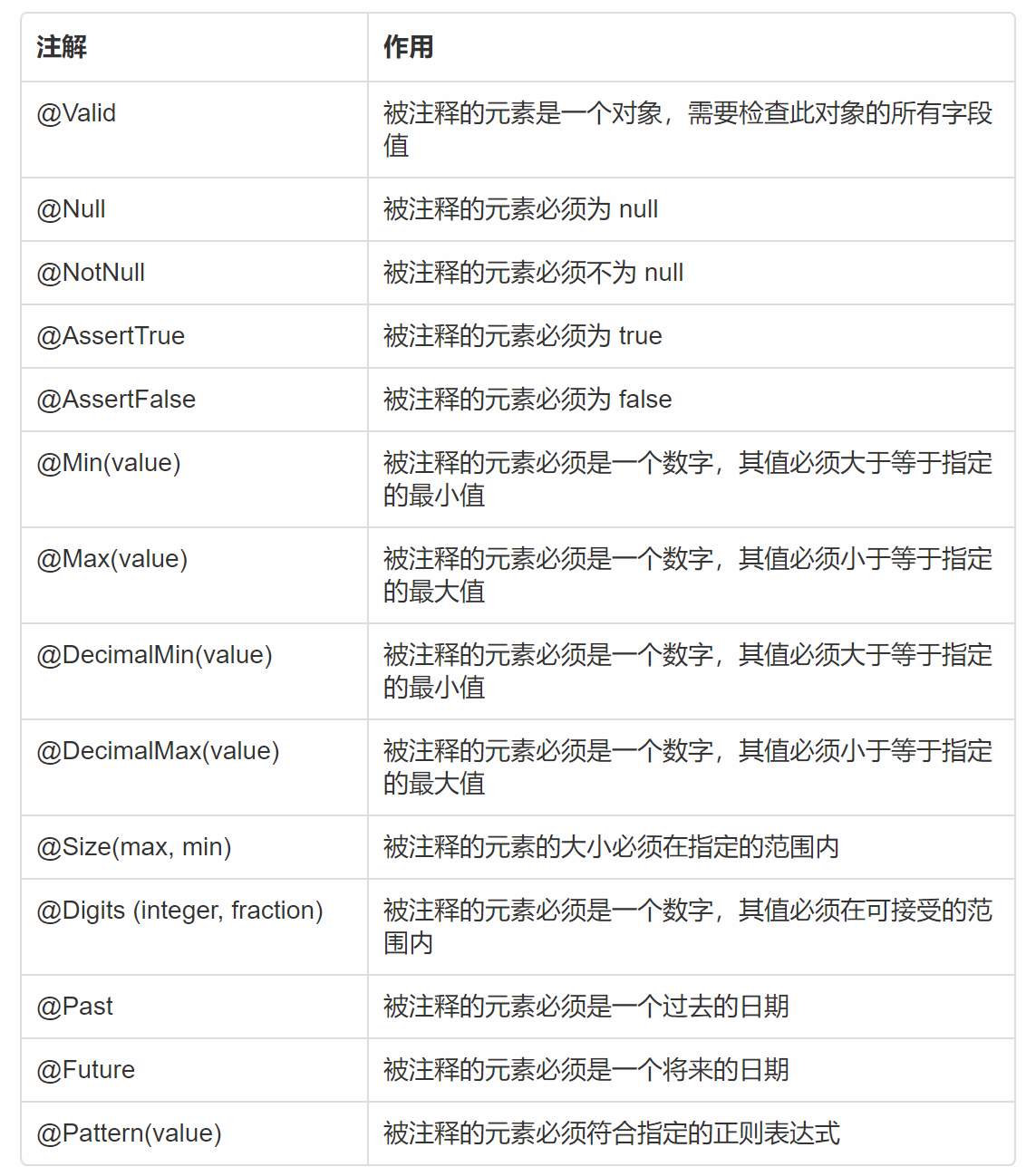
Java Validation参数校验注解使用 前言Hibernate Validator 是 Bean Validation 的参考实现 。Hibernate Validator 提供了 JSR 303 规范中所有内置 constraint 的实现,除此之外还有一些附加的 constraint在日常开发中,Hibernate Validator经常用来验证bean的字段,基于注解,方便快捷高效。在SpringBoot中可以使用 @Validated ,注解Hibernate Validator加强版,也可以使用 @Valid 原来Bean Validation java版本内置校验注解Bean Validation 中内置的 constraintHibernate Validator 附加的 constraintmessage支持表达式和EL表达式 ,比如message = "姓名长度限制为{min}到{max} ${1+2}")想把错误描述统一写到properties的话,在classpath下面新建ValidationMessages_zh_CN.properties文件(注意value需要转换为unicode编码),然后用{}格式的占位符hibernate补充的注解中,最后3个不常用,可忽略。主要区分下@NotNull, @NotEmpty ,@NotBlank 3个注解的区别:@NotNull 任何对象的value不能为null@NotEmpty 集合对象的元素不为0,即集合不为空,也可以用于字符串不为null@NotBlank 只能用于字符串不为null,并且字符串trim()以后length要大于0分组校验如果同一个参数,需要在不同场景下应用不同的校验规则,就需要用到分组校验了。比如:新注册用户还没起名字,我们允许name字段为空,但是在更新时候不允许将名字更新为空字符。分组校验有三个步骤:1 .定义一个分组类(或接口)public interface Update extends Default{ }在校验注解上添加groups属性指定分组public class UserVO { @NotBlank(message = "name 不能为空",groups = Update.class) private String name; // 省略其他代码... }Controller方法的@Validated注解添加分组类@PostMapping("update") public ResultInfo update(@Validated({Update.class}) UserVO userVO) { return new ResultInfo().success(userVO); }自定义的Update分组接口继承了Default接口。校验注解(如: @NotBlank)和@validated默认其他注解都属于Default.class分组,这一点在javax.validation.groups.Default注释中有说明/** * Default Jakarta Bean Validation group. * <p> * Unless a list of groups is explicitly defined: * <ul> * <li>constraints belong to the {@code Default} group</li> * <li>validation applies to the {@code Default} group</li> * </ul> * Most structural constraints should belong to the default group. * * @author Emmanuel Bernard */ public interface Default { }在编写Update分组接口时,如果继承了Default,下面两个写法就是等效的:@Validated({Update.class}),@Validated({Update.class,Default.class})如果Update不继承Default,@Validated({Update.class})就只会校验属于Update.class分组的参数字段递归校验如果 UserVO 类中增加一个 OrderVO 类的属性,而 OrderVO 中的属性也需要校验,就用到递归校验了,只要在相应属性上增加 @Valid 注解即可实现(对于集合同样适用)public class OrderVO { @NotNull private Long id; @NotBlank(message = "itemName 不能为空") private String itemName; // 省略其他代码... }public class UserVO { @NotBlank(message = "name 不能为空",groups = Update.class) private String name; //需要递归校验的OrderVO @Valid private OrderVO orderVO; // 省略其他代码... }自定义校验validation 为我们提供了这么多特性,几乎可以满足日常开发中绝大多数参数校验场景了。但是,一个好的框架一定是方便扩展的。有了扩展能力,就能应对更多复杂的业务场景,毕竟在开发过程中,唯一不变的就是变化本身。 Validation允许用户自定义校验实现很简单,分两步:自定义校验注解package cn.soboys.core.validator; import javax.validation.Constraint; import javax.validation.Payload; import java.lang.annotation.*; /** * 日期验证 约束注解类 */ @Target({ElementType.METHOD, ElementType.FIELD, ElementType.TYPE}) @Retention(RetentionPolicy.RUNTIME) @Documented @Constraint(validatedBy = {IsDateTimeValidator.class}) // 标明由哪个类执行校验逻辑 public @interface IsDateTime { // 校验出错时默认返回的消息 String message() default "日期格式错误"; //分组校验 Class<?>[] groups() default {}; Class<? extends Payload>[] payload() default {}; //下面是我自己定义属性 boolean required() default true; String dateFormat() default "yyyy-MM-dd"; }注意: message 用于显示错误信息这个字段是必须的, groups和payload也是必须的@Constraint(validatedBy = { HandsomeBoyValidator.class})用来指定处理这个注解逻辑的类编写校验者类package cn.soboys.core.validator; import cn.hutool.core.util.StrUtil; import javax.validation.ConstraintValidator; import javax.validation.ConstraintValidatorContext; /** * 日期验证器 */ public class IsDateTimeValidator implements ConstraintValidator<IsDateTime, String> { private boolean required = false; private String dateFormat = "yyyy-MM-dd"; /** * 用于初始化注解上的值到这个validator * @param constraintAnnotation */ @Override public void initialize(IsDateTime constraintAnnotation) { required = constraintAnnotation.required(); dateFormat = constraintAnnotation.dateFormat(); } /** * 具体的校验逻辑 * @param value * @param context * @return */ public boolean isValid(String value, ConstraintValidatorContext context) { if (required) { return ValidatorUtil.isDateTime(value, dateFormat); } else { if (StrUtil.isBlank(value)) { return true; } else { return ValidatorUtil.isDateTime(value, dateFormat); } } } }注意这里验证逻辑我抽出来单独写了一个工具类, ValidatorUtilpackage cn.soboys.core.validator; import cn.hutool.core.date.DateUtil; import cn.hutool.core.text.StrFormatter; import cn.hutool.core.util.NumberUtil; import cn.hutool.core.util.StrUtil; import java.lang.reflect.Method; import java.math.BigDecimal; import java.util.regex.Matcher; import java.util.regex.Pattern; /** * 验证表达式 */ public class ValidatorUtil { private static final Pattern mobile_pattern = Pattern.compile("1\\d{10}"); private static final Pattern money_pattern = Pattern.compile("^[0-9]+\\.?[0-9]{0,2}$"); /** * 验证手机号 * * @param src * @return */ public static boolean isMobile(String src) { if (StrUtil.isBlank(src)) { return false; } Matcher m = mobile_pattern.matcher(src); return m.matches(); } /** * 验证枚举值是否合法 ,所有枚举需要继承此方法重写 * * @param beanClass 枚举类 * @param status 对应code * @return * @throws Exception */ public static boolean isEnum(Class<?> beanClass, String status) throws Exception { if (StrUtil.isBlank(status)) { return false; } //转换枚举类 Class<Enum> clazz = (Class<Enum>) beanClass; /** * 其实枚举是语法糖 * 是封装好的多个Enum类的实列 * 获取所有枚举实例 */ Enum[] enumConstants = clazz.getEnumConstants(); //根据方法名获取方法 Method getCode = clazz.getMethod("getCode"); Method getDesc = clazz.getMethod("getDesc"); for (Enum enums : enumConstants) { //得到枚举实例名 String instance = enums.name(); //执行枚举方法获得枚举实例对应的值 String code = getCode.invoke(enums).toString(); if (code.equals(status)) { return true; } String desc = getDesc.invoke(enums).toString(); System.out.println(StrFormatter.format("实列{}---code:{}desc{}", instance, code, desc)); } return false; } /** * 验证金额0.00 * * @param money * @return */ public static boolean isMoney(BigDecimal money) { if (StrUtil.isEmptyIfStr(money)) { return false; } if (!NumberUtil.isNumber(String.valueOf(money.doubleValue()))) { return false; } if (money.doubleValue() == 0) { return false; } Matcher m = money_pattern.matcher(String.valueOf(money.doubleValue())); return m.matches(); } /** * 验证 日期 * * @param date * @param dateFormat * @return */ public static boolean isDateTime(String date, String dateFormat) { if (StrUtil.isBlank(date)) { return false; } try { DateUtil.parse(date, dateFormat); return true; } catch (Exception e) { return false; } } }我自定义了补充了很多验证器,包括日期验证,枚举验证,手机号验证,金额验证自定义校验注解使用起来和内置注解无异,在需要的字段上添加相应注解即可校验流程解析使用 Validation API 进行参数效验步骤整个过程如下图所示,用户访问接口,然后进行参数效验 ,如果效验通过,则进入业务逻辑,否则抛出异常,交由全局异常处理器进行处理
-
mysql位置距离排序功能实现 再实际的开发中,我们经常需要使用地理经纬度信息来做排序,比如查找附近的门店,或查找离我最近的人的需求等。可直接套用下方mysql查询语句进行数据查询排序sql中latitude为数据库表中的纬度,longitude代表经度{latitude} 代表传入的纬度,{latitude} 代表传入的经度,主要为用户当前位置信息,查询获得结果 distance 单位为米SELECT *, (round(6367000 * 2 * asin(sqrt(pow(sin(((latitude * pi()) / 180 - (${latitude} * pi()) / 180) / 2), 2) + cos((${latitude} * pi()) / 180) * cos((latitude * pi()) / 180) * pow(sin(((longitude * pi()) / 180 - (${longitude} * pi()) / 180) / 2), 2))))) AS distance FROM ec_store WHERE is_show = 1 and is_del = 0 ORDER BY distance asc
-
Mybatis plus 代码生成,提高开发效率 使用mybatis generator 工具可生成代码第一步 pom.xml中 引入依赖下发引入generator 包与模板引擎velocity包 <dependency> <groupId>com.baomidou</groupId> <artifactId>mybatis-plus-generator</artifactId> <version>3.3.1</version> </dependency> <dependency> <groupId>org.apache.velocity</groupId> <artifactId>velocity-engine-core</artifactId> <version>2.3</version> </dependency>新建类,执行main文件public class GeneratorTest { //代码生成保存目录 private final static String out="J:\\DEMO\\code\\api-server\\tmp"; //JDBC数据源 private final static String jdbc="jdbc:mysql://localhost:3306/java_dev?useUnicode=true&useSSL=false&characterEncoding=utf8"; //数据库账号 private final static String db_user="root"; //数据库密码 private final static String db_paswword="root"; //表前缀 private final static String table_prefix="eb_"; //包名 private static final String package_name="com.gxxblw.web"; private static final String author="哈根达斯"; public static void main(String[] args) { AutoGenerator mpg = new AutoGenerator(); File file=new File(out); File[] files= file.listFiles(); for (int i=0;i<files.length;i++){ files[i].deleteOnExit(); } // 全局配置 GlobalConfig gc = new GlobalConfig(); gc.setOutputDir(out); gc.setAuthor(author); gc.setOpen(true); //自定义Mappter文件名 gc.setMapperName("%sDao"); gc.setSwagger2(true); //实体属性 Swagger2 注解 mpg.setGlobalConfig(gc); // 数据源配置 DataSourceConfig dsc = new DataSourceConfig(); dsc.setUrl(jdbc); // dsc.setSchemaName("public"); dsc.setDriverName("com.mysql.jdbc.Driver"); dsc.setUsername(db_user); dsc.setPassword(db_paswword); mpg.setDataSource(dsc); /*TemplateConfig templateConfig = new TemplateConfig(); templateConfig.setMapper("dao"); templateConfig.setEntityKt("domain"); templateConfig.setXml(null); mpg.setTemplate(templateConfig);*/ // 包配置 PackageConfig pc = new PackageConfig(); pc.setModuleName(scanner("模块名")); pc.setParent(package_name); pc.setMapper("dao"); pc.setEntity("model"); mpg.setPackageInfo(pc); // 策略配置 StrategyConfig strategy = new StrategyConfig(); strategy.setNaming(NamingStrategy.underline_to_camel); strategy.setColumnNaming(NamingStrategy.underline_to_camel); strategy.setEntityLombokModel(true); strategy.setRestControllerStyle(true); strategy.setInclude(scanner("表名,多个英文逗号分割").split(",")); strategy.setTablePrefix(table_prefix); mpg.setStrategy(strategy); mpg.setTemplateEngine(new VelocityTemplateEngine()); mpg.execute(); } public static String scanner(String tip) { Scanner scanner = new Scanner(System.in); StringBuilder help = new StringBuilder(); help.append("请输入" + tip + ":"); System.out.println(help.toString()); if (scanner.hasNext()) { String ipt = scanner.next(); if (StringUtils.isNotBlank(ipt)) { return ipt; } } throw new MybatisPlusException("请输入正确的" + tip + "!"); } }执行成功后保存目录将生成模板代码,更多参数可查看文档 查看代码生成
-
Spring Boot 中注解@Scheduled实现定时任务 在编写Spring Boot应用中经常会遇到这样的场景,比如:我需要定时地发送一些短信、邮件之类的操作,也可能会定时地检查和监控一些标志、参数等。1.创建定时任务在Spring Boot中编写定时任务是非常简单的事,下面通过实例介绍如何在Spring Boot中创建定时任务,实现每过5秒输出一下当前时间。在Spring Boot的主类中加入 @EnableScheduling 注解,启用定时任务的配置@SpringBootApplication @EnableScheduling public class Application { public static void main(String[] args) { SpringApplication.run(Application.class, args); } }2.创建定时任务实现类@Component public class ScheduledTasks { private static final SimpleDateFormat dateFormat = new SimpleDateFormat("HH:mm:ss"); @Scheduled(fixedRate = 5000) public void reportCurrentTime() { log.info("现在时间:" + dateFormat.format(new Date())); } }运行程序,控制台中可以看到类似如下输出,定时任务开始正常运作了。2021-07-13 14:56:56.413 INFO 34836 --- [ main] c.d.chapter71.Chapter71Application : Started Chapter71Application in 1.457 seconds (JVM running for 1.835) 2021-07-13 14:57:01.411 INFO 34836 --- [ scheduling-1] com.didispace.chapter71.ScheduledTasks : 现在时间:14:57:01 2021-07-13 14:57:06.412 INFO 34836 --- [ scheduling-1] com.didispace.chapter71.ScheduledTasks : 现在时间:14:57:06 2021-07-13 14:57:11.413 INFO 34836 --- [ scheduling-1] com.didispace.chapter71.ScheduledTasks : 现在时间:14:57:11 2021-07-13 14:57:16.413 INFO 34836 --- [ scheduling-1] com.didispace.chapter71.ScheduledTasks : 现在时间:14:57:163.@Scheduled 详解在上面的入门例子中,使用了 @Scheduled(fixedRate = 5000) 注解来定义每过5秒执行的任务。对于 @Scheduled 的使用,我们从源码里看看有哪些配置:@Target({ElementType.METHOD, ElementType.ANNOTATION_TYPE}) @Retention(RetentionPolicy.RUNTIME) @Documented @Repeatable(Schedules.class) public @interface Scheduled { String CRON_DISABLED = ScheduledTaskRegistrar.CRON_DISABLED; String cron() default ""; String zone() default ""; long fixedDelay() default -1; String fixedDelayString() default ""; long fixedRate() default -1; String fixedRateString() default ""; long initialDelay() default -1; String initialDelayString() default ""; }这些具体配置信息的含义如下:cron:通过cron表达式来配置执行规则zone:cron表达式解析时使用的时区fixedDelay:上一次执行结束到下一次执行开始的间隔时间(单位:ms)fixedDelayString:上一次任务执行结束到下一次执行开始的间隔时间,使用java.time.Duration#parse解析fixedRate:以固定间隔执行任务,即上一次任务执行开始到下一次执行开始的间隔时间(单位:ms),若在调度任务执行时,上一次任务还未执行完毕,会加入worker队列,等待上一次执行完成后立即执行下一次任务fixedRateString:与fixedRate逻辑一致,只是使用java.time.Duration#parse解析initialDelay:首次任务执行的延迟时间initialDelayString:首次任务执行的延迟时间,使用java.time.Duration#parse解析4.思考与进阶是不是这样实现定时任务很简单呢?那么继续思考一下这种实现方式是否存在什么弊端呢?可能初学者不太容易发现问题,但如果你已经有一定的线上项目经验的话,问题也是显而易见的:这种模式实现的定时任务缺少在集群环境下的协调机制。什么意思呢?假设,我们要实现一个定时任务,用来每天网上统计某个数据然后累加到原始数据上。我们开发测试的时候不会有问题,因为都是单进程在运行的。但是,当我们把这样的定时任务部署到生产环境时,为了更高的可用性,启动多个实例是必须的。此时,时间一到,所有启动的实例就会同时开始执行这个任务。那么问题也就出现了,因为有累加操作,最终我们的结果就会出现问题。解决这样问题的方式很多种,比较通用的就是采用分布式锁的方式,让同类任务之前的时候以分布式锁的方式来控制执行顺序,比如:使用Redis、Zookeeper等具备分布式锁功能的中间件配合就能很好的帮助我们来协调这类任务在集群模式下的执行规则。参考文献原文链接