搜索到
110
篇与
哈根达斯
的结果
-
 Maven中设置依赖引用第三方jar,并打包部署 目录有很多jar包我们在maven远程仓库中无法下载时,需要在项目中添加依赖怎么处理呢?第一步:将jar包放到放到项目resource下lib文件夹中,如无此文件夹,请先创建,再将jar放进去<!--以下内存根据实际情况自定义填写--> <dependency> <groupId>org.demo</groupId> <artifactId>demo-core</artifactId> <version>1.0.0</version> <scope>system</scope> <systemPath>${project.basedir}/src/main/resources/libs/demo.jar</systemPath> </dependency> 第二步:添加完成后我们此时ide已经可以正常的进行获取包内的文件,并进行开发,但是我们打包后发现找不到类,此时我们需要在插件配置项添加如下代码. <plugins> <plugin> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-maven-plugin</artifactId> <!--解决本地jar包打不进jar的问题--> <configuration> <includeSystemScope>true</includeSystemScope> </configuration> </plugin> </plugins> 我们在重新打包使用 mvn clean package -Dmaven.test.skip=true,重新运行后发现已经可以正常了
Maven中设置依赖引用第三方jar,并打包部署 目录有很多jar包我们在maven远程仓库中无法下载时,需要在项目中添加依赖怎么处理呢?第一步:将jar包放到放到项目resource下lib文件夹中,如无此文件夹,请先创建,再将jar放进去<!--以下内存根据实际情况自定义填写--> <dependency> <groupId>org.demo</groupId> <artifactId>demo-core</artifactId> <version>1.0.0</version> <scope>system</scope> <systemPath>${project.basedir}/src/main/resources/libs/demo.jar</systemPath> </dependency> 第二步:添加完成后我们此时ide已经可以正常的进行获取包内的文件,并进行开发,但是我们打包后发现找不到类,此时我们需要在插件配置项添加如下代码. <plugins> <plugin> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-maven-plugin</artifactId> <!--解决本地jar包打不进jar的问题--> <configuration> <includeSystemScope>true</includeSystemScope> </configuration> </plugin> </plugins> 我们在重新打包使用 mvn clean package -Dmaven.test.skip=true,重新运行后发现已经可以正常了 -
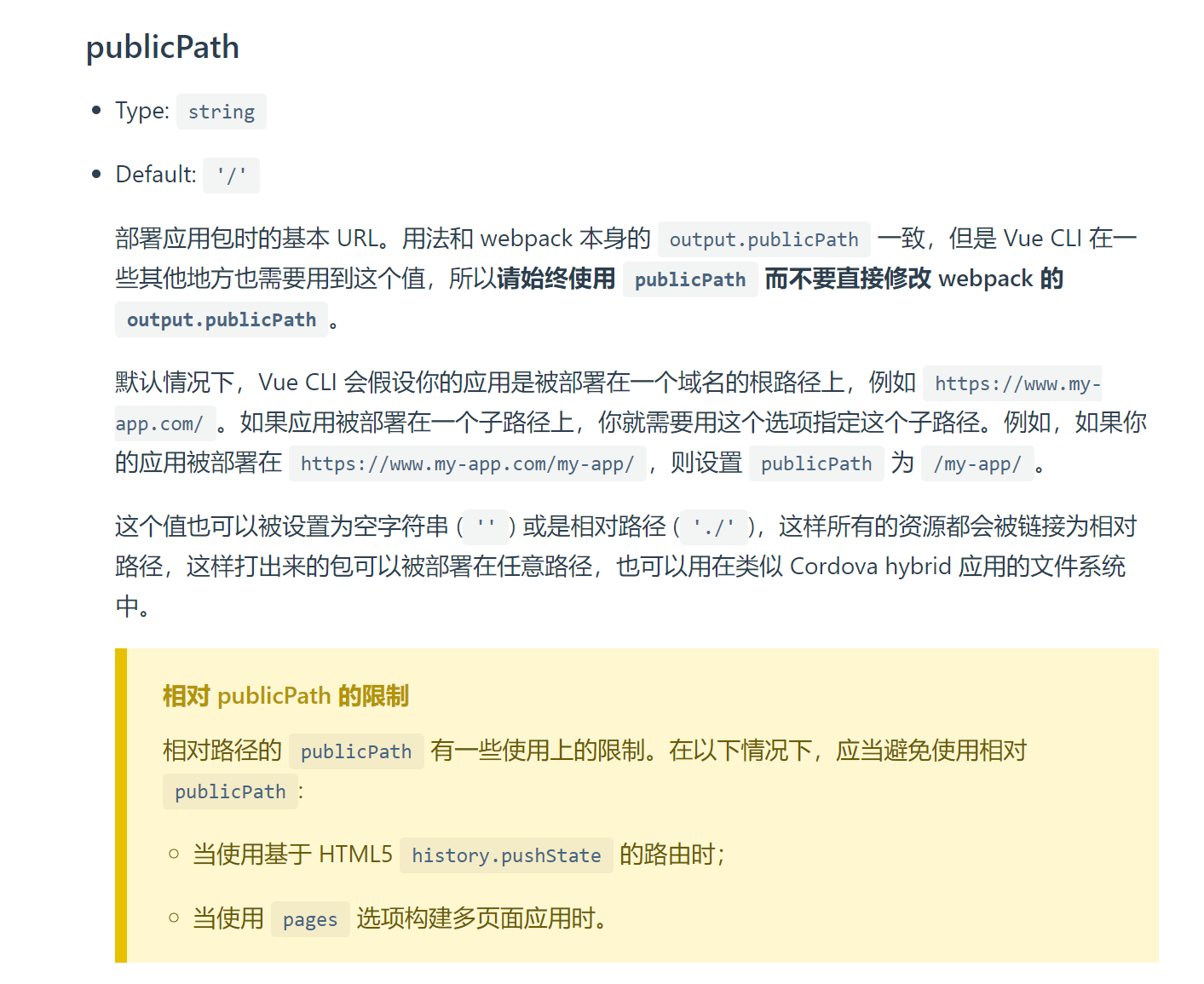
Vue项目中设置路由为二级目录访问 在日常的开发工作中,我们经常遇需要把多个项目和服务部署在同一个域名下,然后使用nginx进行代理转发,例如:接口服务:a.com/api, 接口服务对应Java或PHP后台应用首页服务前端工程:a.com , 前端服务使用Vue编写后台服务前端工程:a.com/system,管理后台服务使用Vue编写,使用二级目录system因项目都需要部署在同一个域名,我们vue需要坐如何设置才能满足要求?了解vue-cli在vue的项目中,我们的项目编译和构建依赖于构建编译工具,所以我们需要对当前项目的cli版本或vite版本有所了解并到官网查看对应的API和配置说明:vue-cli 方式第一步,我们需要在vue.config.js文件中新增publicPath配置项,具体的参数说明如下:更多说明查看官网说明: vue-cli官网介绍 建议实际项目中使用条件式参数,或者在配置文件中设置值,参考代码如下:const vueConfig = { publicPath: process.env.NODE_ENV === 'production' ? '/system/' : '/', }第二步,修改路由配置,const createRouter = () => new Router({ mode: process.env.NODE_ENV === 'production' ? 'history' : 'hash',// 路由访问模式,可选参数,如果试history,则nginx需要做额外的配置 base: process.env.NODE_ENV === 'production' ? '/system/' : '/',// 访问基础路径,重要设置 routes: routerMap // 你的路由配置 }) const router = createRouter() export default router第三步修改nginx配置信息:当我们的路由使用history模式访问时,需对配置进行修改server { listen 80; server_name a.com; root /home/projectWork; #项目根目录 #后台服务 location /system { index index.html; try_files $uri $uri/ /system/index.html; #重要,vue项目解决刷新后404问题,配置项为重试查找别的文件,具体配置请自行百度"nginx try_files" alias /home/projectWork/system; } # 接口服务 location /api { proxy_pass http://127.0.0.1:8501; proxy_set_header Host $host; proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_hide_header X-Powered-By; proxy_set_header Upgrade $http_upgrade; proxy_set_header Connection "Upgrade"; } }至此我们把system项目打包编译后的文件放到网站本目录下的system目录下,使用路径a.com/system 访问即可访问到我们的服务.
-
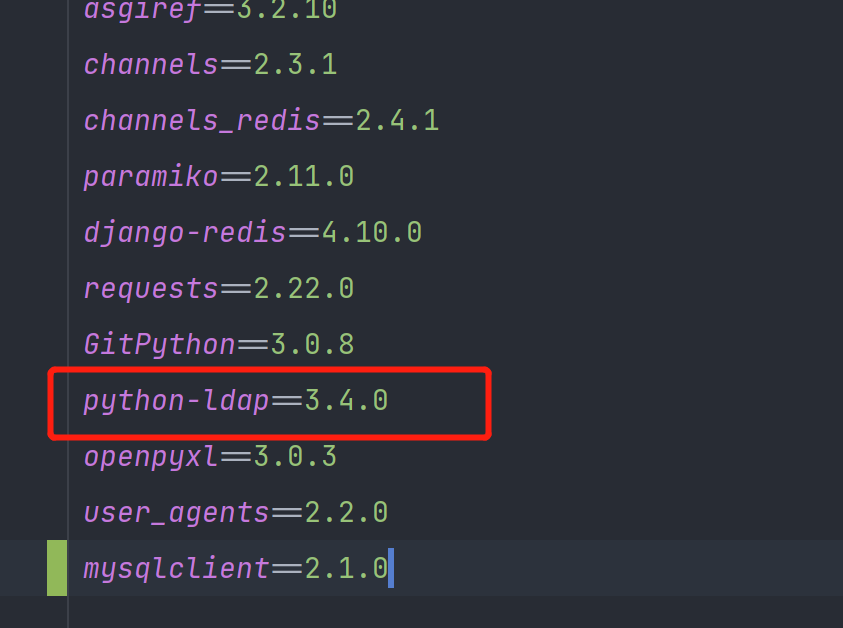
python-ldap模块无法下载安装处理 今天下载一个python项目运行,python-ldap模块一直无法下载,所以百度查了下资料,需要独立下载进行安装下载whl文件点击下发链接,根据项目自身要求版本进行下载,我这里需要的3.4.0,并且python是3.8.*的版本 点击下载 在命令行下执行安装命令pip3 install python_ldap‑3.4.0‑cp38‑cp38‑win_amd64.whl 提示安装成功即可。其它问题如果你使用pycharm的venv环境进行开发,则需要在项目下进入venv/Scripts目录下运行以下名利# 进入虚拟环境目录 cd venv/Scripts # 激活虚拟环境 activate.bat # 安装whl模块文件 pip3 install python_ldap‑3.4.0‑cp38‑cp38‑win_amd64.whl
-
-
python 第三方库大全 Python的强大之处除了它的简洁易用,最厉害的就是它有着广泛的第三方库支持。今天小编就带你看下Python有哪些常用第三库吧, 知道且用过超过10个的欢迎留言~文本处理与格式转换Chardet 字符编码探测器,可以自动检测文本、网页、xml的编码。colorama 主要用来给文本添加各种颜色,并且非常简单易用。Prettytable 主要用于在终端或浏览器端构建格式化的输出。difflib,[Python]标准库,计算文本差异Levenshtein,快速计算字符串相似度。fuzzywuzzy 字符串模糊匹配。esmre 正则表达式的加速器。shortuuid 一组简洁URL/UUID函数库。ftfy,Unicode文本工具7unidecode,ascii和Unicode文本转换函数。xpinyin,将汉字转换为拼音的函数库pangu.py,调整对中日韩文字当中的字母、数字间距。pyfiglet,Python写的figlet程序,使用字符组成ASCII艺术图片uniout,提取字符串中可读写的字符awesome slugify,一个Python slugify库,用于处理Unicode。python-slugify,转换Unicode为ASCII内码的slugify函数库。unicode-slugify,生成unicode内码,Django的依赖包。ply,Python版的lex和yacc的解析工具phonenumbers,解析电话号码,格式,存储和验证的国际电话号码。python-user-agents,浏览器的用户代理(user-agents)的解析器。sqlparse,SQL解析器。pygments,一个通用的语法高亮工具。python-nameparser,解析人名,分解为单独的成分。pyparsing,通用解析器生成框架。tablib,表格数据格式,包括,XLS、CSV,JSON,YAML。python-docx,docx文档读取,查询和修改,微软Word 2007 / 2008的docx文件。xlwt/xlrd,读写Excel格式的数据文件。xlsxwriter,创建Excel格式的xlsx文件。xlwings,利用Python调用Excelcsvkit,CSV文件工具包。marmir,把Python[数据结构],转化为电子表格。pdfminer,从PDF文件中提取信息。pypdf2, 合并和转换PDF页面的函数库。Python-Markdown,轻量级标记语言Markdown的Python实现。Mistune,,快速、全功能的纯Python编写的Markdown解释器。dateutil,标准的Python官方datetime模块的扩展包,字符串日期工具,其中parser是根据字符串解析成datetime,而rrule是则是根据定义的规则来生成datetime。arrow,更好的日期和时间处理Python库chronyk,一个Python 3版函数库,用于解析人写的时间和日期。delorean,清理期时间的函数库。when.py,为见的日期和时间,提供人性化的功能。moment,类似Moment.js的日期/时间Python库pytz,世界时区,使用tz database时区信息[数据库]BeautifulSoup,基于Python的HTML/XML解析器,简单易用, 功能很强大,即使是有bug,有问题的html代码,也可以解析。lxml,快速,易用、灵活的HTML和XML处理库,功能超强,在遇到有缺陷、不规范的xml时,Python自带的xml处理器可能无法解析。报错时,程序会尝试再用lxml的修复模式解析。htmlparser,官方版解析HTML DOM树,偶尔搞搞命令行自动表单提交用得上。pyyaml,Python版本的YAML解释器。html5lib,-标准库,解析和序列化HTML文档和片段。pyquery,类似[jQuery]的的HTML解释器函数库。cssutils,Python CSS库。MarkupSafe,XML或HTML / XHTML安全字符串标记工具。cssutils - ACSS library for Python., MarkupSafe - Implements a XML/HTML/XHTMLbleach,漂白,基于HTML的白名单函数库。xmltodict,类似JSON的XML工具包。xhtml2pdf,HTML / CSS格式转换器,看生成pdf文档。untangle,把XML文档,转换为Python对象,方便访问。文件处理库名称简介Mimetypes,Python标准库,映射文件名到MIME类型。imghdr,Python标准库,确定图像类型。python-magic,libmagic文件类型识别库,Python接口格式。path.py,os.path模块的二次封装。watchdog,一组API和shell实用程序,用于监视文件系统事件。Unipath,面向对象的文件/目录的操作工具包。pathlib,-(Python 3.4版已经作为Python标准库),一个跨平台,面向path的函数库。pickle/cPickle,python的pickle模块实现了基本的数据序列和反序列化。通过pickle模块的序列化操作我们能够将程序中运行的对象信息保存到文件中去,永久存储;通过pickle模块的反序列化操作,我们能够从文件中创建上一次程序保存的对象。cPickle是[C语言]实现的版本,速度更快。ConfigParser,Python标准库,INI文件解析器。configobj,INI文件解析器。config,分层次配置,logging作者编写。profig,多格式配置转换工具。logging,Python标准库,日志文件生成管理函数库。logbook,logging的替换品。Sentry,实时log服务器。Raven,哨兵Sentry的Python客户端。Sphinx,斯芬克斯(狮身人面像),Python文档生成器。reStructuredText,标记语法和解析工具,Docutils组件。mkdocs,Markdown格式文档生成器。pycco,简单快速、编程风格的文档生成器。pdoc,自动生成的Python库API文档epydoc,从源码注释中生成各种格式文档的工具图像处理库名称简介PIL(Python Image Library),基于Python的图像处理库,功能强大,对图形文件的格式支持广泛,内置许多图像处理函数,如图像增强、滤波[算法]等。Pillow,图像处理库,PIL图像库的分支和升级替代产品。Matplotlib,著名的绘图库,提供了整套和matlab相似的命令API,用以绘制一些高质量的数学二维图形,十分适合交互式地进行制图。brewer2mpl,有一个专业的python配色工具包,提供了从美术角度来讲的精美配色。PyGame基于Python的多媒体开发和游戏软件开发模块,包含大量游戏和图像处理功能。Box2d,开源的2d物理引擎,愤怒的小鸟就是使用了这款物理引擎进行开发的,Box2d物理引擎内部模拟了一个世界,你可以设置这个世界里的重力,然后往这个世界里添加各种物体,以及他们的一些物理特性,比如质量,摩擦,阻尼等等。Pymunk,类似box2d的开源物理图形模拟库。OpenCV, 目前最好的开源图像/视觉库,包括图像处理和计算机视觉方面、[机器学习]的很多通用算法。SimpleCV,计算机视觉开源框架,类似opencv。VTK,视觉化工具函式库(VTK, Visualization Toolkit)是一个开放源码,跨平台、支援平行处理(VTK曾用于处理大小近乎1个Petabyte的资料,其平台为美国Los Alamos国家实验室所有的具1024个处理器之大型系统)的图形应用函式库。2005年时曾被美国陆军研究实验室用于即时模拟俄罗斯制反导弹战车ZSU23-4受到平面波攻击的情形,其计算节点高达2.5兆个之多。cgkit,Python Computer Graphics Kit,其module 主要分两个部分1.与3d相关的一些python module 例如the vector, matrix and quaternion types, the RenderMan bindings, noise functions 这些模块可以在maya houdini nuke blender 等有Python扩展的程序中直接用;提供完整的场景操作的module, 他类似其他三维软件,在内存中保留完整的描述场景的信息。不能直接用于maya 等。CGAL,Computational Geometry Algorithms Library,计算几何算法库,提供计算几何相关的数据结构和算法,诸如三角剖分(2D约束三角剖分及二维和三维Delaunay三角剖分),Voronoi图(二维和三维的点,2D加权Voronoi图,分割Voronoi图等),多边形(布尔操作,偏置),多面体(布尔运算),曲线整理及其应用,网格生成(二维Delaunay网格生成和三维表面和体积网格生成等),几何处理(表面网格简化,细分和参数化等),凸壳算法(2D,3D和dD),搜索结构(近邻搜索,kd树等),插值,形状分析,拟合,距离等。Aggdraw,开源图像库,几乎涵盖了2d image操作的所有功能,使用起来非常灵活。Pycairo,开源矢量绘图库Cairo开罗的python接口,cairo提供在多个背景下做2-D的绘图,高级的更可以使用硬件加速功能。wand,Python绑定魔杖工具(MagickWand),C语言API接口。thumbor, -智能成像工具,可调整大小和翻转图像。imgSeek,查询相似的图像。python-qrcode,纯Python的二维码(QR码)生成器。pyBarcode,创建条码,无需PIL模块。pygram,Instagram像图像过滤器。Quads,基于四叉树的计算机艺术。nude.py,裸体检测函数。scikit-image,scikit工具箱的图像处理库。hmap,图像直方图工具。bokeh,交互的Web绘图。plotly,Web协同的Python和Matplotlib绘制。vincent,文森特,Python Vega的函数库。d3py,Python绘图库,基于D3.JS, ggplot -API兼容R语言的ggplot2.Kartograph.py,在Python绘制漂亮的SVG地图。pygal, SVG图表的创造者。pygraphviz,Graphviz的Python接口。Fonttlools,ttf字体工具函数包,用于fontforge、ttx等字体软件。游戏和多媒体库名称简介audiolazy,数字信号处理(DSP)的Python工具包。audioread,跨平台(GStreamer + Core Audio + MAD + FFmpeg)音频解码库。beets,音乐库管理。dejavu,音频指纹识别算法。Dejavu 听一次音频后就会记录该音频的指纹信息,然后可通过麦克风对输入的音频进行识别是否同一首歌。django-elastic-transcoder,Django +亚马逊elastic转码。eyeD3,音频文件工具,特别是MP3文件包含的ID3元数据。id3reader,用于读取MP3的元数据。mutagen,处理音频元数据。pydub,-操纵音频和简单的高层次的接口。pyechonest,Echo Nest API客户端。talkbox,语音和信号处理的Python库。TimeSide,开放的网络音频处理框架。tinytag,读取音乐文件元数据,包括的MP3,OGG,FLAC和wave文件。m3u8,用于解析m3u8文件。moviepy,多格式视频编辑脚本模块,包括GIF动画。shorten.tv,视频摘要。scikit视频,SciPy视频处理例程。GeoDjango,一个世界级的地理Web框架。geopy,Geo地理编码的工具箱。pygeoip,纯Python写的GeoIP API。GeoIP,Python API接口,使用高精度GeoIP Legacy Database数据库。geojson,GeoJSON函数库django-countries,一个Django程序,提供国家选择,国旗图标的静态文件,和一个国家的地域模型。Pygame,Python游戏设计模块。Cocos2d,2D游戏框架,演示,和其他的图形/交互应用,基于pyglet。Cocos2d- cocos2d is a framework for building 2D games, demos, and other graphical/interactive applications. It is based on pyglet.,PySDL2,SDL2的封装库。Panda3D- 3D游戏引擎,迪士尼开发。用C++写的,完全兼容Python。PyOgre,OGRE 3D渲染引擎,可用于游戏,模拟,任何3D。PyOpenGL,绑定OpenGL和它相关的API。PySFML,Python绑定SFMLRenPy,视觉小说引擎。大数据与科学计算库名称简介pycuda/opencl,GPU高性能并发计算Pandas,python实现的类似R语言的数据统计、分析平台。基于NumPy和Matplotlib开发的,主要用于数据分析和数据可视化,它的数据结构DataFrame和R语言里的data.frame很像,特别是对于时间序列数据有自己的一套分析机制,非常不错。Open Mining,商业智能(BI),Pandas的Web界面。blaze,NumPy和Pandas大数据界面。SciPy,开源的Python算法库和数学工具包,SciPy包含的模块有最优化、线性代数、积分、插值、特殊函数、快速傅里叶变换、信号处理和图像处理、常微分方程求解和其他科学与工程中常用的计算。其功能与软件MATLAB、Scilab和GNU Octave类似。Numpy和Scipy常常结合着使用,Python大多数机器学习库都依赖于这两个模块。ScientificPython,一组经过挑选的Python程序模块,用于科学计算,包括几何学(矢量、张量、变换、矢量和张量场),四元数,自动求导数,(线性)插值,多项式,基础统计学,非线性最小二乘拟合,单位计算,Fortran兼容的文本格式,通过VRML的3D显示,以及两个Tk小工具,分别用于绘制线图和3D网格模型。此外还具有到netCDF,MPI和BSPlib库的接口。NumPy科学计算库,提供了矩阵,线性代数,傅立叶变换等等的解决方案, 最常用的是它的N维数组对象. NumPy提供了两种基本的对象:ndarray(N-dimensional array object)和 ufunc(universal function object)。ndarray是存储单一数据类型的多维数组,而ufunc则是能够对数组进行处理的函数。Cvxopt,最优化计算包,可进行线性规划、二次规划、半正定规划等的计算。Numba,科学计算速度优化编译器。pymvpa2,是为大数据集提供统计学习分析的Python工具包,它提供了一个灵活可扩展的框架。它提供的功能有分类、回归、特征选择、数据导入导出、可视化等。NetworkX,复杂网络的优化软件包。zipline,交易算法的函数库。PyDy, Python动态建模函数库。SymPy,符号数学的Python库。statsmodels,Python的统计建模和计量经济学。astropy,天文学界的Python库。orange,橙色,数据挖掘,数据可视化,通过可视化编程或Python脚本学习机分析。RDKit,化学信息学和机器学习的软件。Open Babel,巴贝尔,开放的化学工具箱。cclib,化学软件包的计算函数库。Biopython,免费的生物计算工具包。bccb,生物分析相关的代码集。bcbio-nextgen,提供完全自动化、高通量、测序分析的工具包。visvis, 可视化计算模块库,可进行一维到四维数据的可视化。MapReduce是Google提出的一个软件[架构],用于大规模数据集(大于1TB)的并行运算。概念“Map(映射)”和“Reduce(归纳)”,及他们的主要思想,都是从函数式编程语言借来的MapReduce函数库。Framworks and libraries for MapReduce.,PySpark,[Spark]的Python API。dpark,Spark的Python克隆,Python中的MapReduce框架。luigi,为批量工作,建立复杂的管道。mrjob,运行在[Hadoop],或亚马逊网络服务的,MapReduce工作。人工智能与机器学习库名称简介NLTK(natural language toolkit),是python的自然语言处理工具包。2001年推出,包括了大量的词料库,以及自然语言处理方面的算法实现:分词, 词根计算, 分类, 语义分析等。Pattern,数据挖掘模块,包括自然语言处理,机器学习工具,等等。textblob,提供API为自然语言处理、分解NLP任务。基于NLTK和Pattern模块。jieba,结巴,中文分词工具。snownlp,用于处理中文文本库。loso,中文分词函数库。genius,中文CRF基础库,条件随机场(conditional random field,简称 CRF),是一种鉴别式机率模型,是随机场的一种,常用于标注或分析序列资料,如自然语言文字或是生物序列。Gensim,一个相当专业的主题模型Python工具包,无论是代码还是文档,可用于如何计算两个文档的相似度LIBSVM,是台湾大学林智仁(Lin Chih-Jen)教授等开发设计的一个简单、易于使用和快速有效的SVM模式识别与回归的软件包,他不但提供了编译好的可在Windows系列系统的执行文件,还提供了源代码,方便改进、修改以及在其它[操作系统]上应用;该软件对SVM所涉及的参数调节相对比较少,提供了很多的默认参数,利用这些默认参数可以解决很多问题;并提供了交互检验(Cross Validation)的功能。该软件可以解决C-SVM、ν-SVM、ε-SVR和ν-SVR等问题,包括基于一对一算法的多类模式识别问题。scikits.learn,构建在SciPy之上用于机器学习的 Python 模块。它包括简单而高效的工具,可用于数据挖掘和数据分析。涵盖分类,回归和聚类算法,例如SVM, 逻辑回归,朴素贝叶斯,随机森林,k-means等算法,代码和文档都非常不错,在许多Python项目中都有应用。例如在我们熟悉的NLTK中,分类器方面就有专门针对scikit-learn的接口,可以调用scikit-learn的分类算法以及训练数据来训练分类器模型。PyMC,机器学习采样工具包,scikit-learn似乎是所有人的宠儿,有人认为,PyMC更有魅力。PyMC主要用来做Bayesian分析。Orange,基于组件的数据挖掘和机器学习软件套装,它的功能即友好,又很强大,快速而又多功能的可视化编程前端,以便浏览数据分析和可视化,包含了完整的一系列的组件以进行数据预处理,并提供了数据帐目,过渡,建模,模式评估和勘探的功能。侧重数据挖掘,可以用可视化语言或Python进行操作,拥有机器学习组件,还具有生物信息学以及文本挖掘的插件。Milk,机器学习工具箱,其重点是提供监督分类法与几种有效的分类分析:SVMs(基于libsvm),K-NN,随机森林经济和决策树。它还可以进行特征选择。这些分类可以在许多方面相结合,形成不同的分类系统。对于无监督学习,它提供K-means和affinity propagation聚类算法。PyMVPA(Multivariate Pattern Analysis in Python),是为大数据集提供统计学习分析的Python工具包,它提供了一个灵活可扩展的框架。它提供的功能有分类、回归、特征选择、数据导入导出、可视化等。NuPIC,开源人工智能平台。该项目由Grok(原名 Numenta)公司开发,其中包括了公司的算法和软件架构。NuPIC 的运作接近于人脑,“当模式变化的时候,它会忘掉旧模式,记忆新模式”。如人脑一样,CLA 算法能够适应新的变化。Pylearn2,-基于Theano的机器学习库。hebel,GPU加速,[深度学习]Python库。gensim,机器学习库。pybrain,机器学习模块,它的目标是为机器学习任务提供灵活、易应、强大的机器学习算法。pybrain包括神经网络、强化学习(及二者结合)、无监督学习、进化算法。以神经网络为核心,所有的训练方法都以神经网络为一个实例Mahout,是 Apache Software Foundation(ASF) 旗下的一个开源项目,提供一些可扩展的机器学习领域经典算法的实现,旨在帮助开发人员更加方便快捷地创建智能应用程序。Mahout包含许多实现,包括聚类、分类、推荐过滤、频繁子项挖掘。此外,通过使用 Apache Hadoop 库,Mahout 可以有效地扩展到云中。Crab,灵活的,快速的推荐引擎。python-recsys,娱乐系统分析,推荐系统。vowpal_porpoise,Vowpal Wabbit轻量级Python封装。Theano,用来定义、优化和模拟数学表达式计算,用于高效的解决多维数组的计算问题的python软件包。它使得写深度学习模型更加容易,同时也给出了一些关于在GPU上训练它们的选项。系统与命令行库名称简介threading,Python标准线程库,更高级别的线程接口。envoy,特使,Python子线程的函数库。sh,成熟的子线程替换函数库。sarge,封装线程。subprocess,调用shell命令的神器argparse,写命令行脚本必备,强大的命令行差数解析工具timeit,计算代码运行的时间等等unp,命令行工具,解压文件。eventlet开销很少的多线程模块,使用的是 green threads 概念,例如,pool = eventlet.GreenPool(10000) 这样一条语句便创建了一个可以处理 10000 个客户端连接的线程池。类似Gevent线程库Gevent,多线程模块pytools,著名的python通用函数、工具包SendKeys, 键盘鼠标操作模块, 模拟键盘鼠标模拟操作。pyHook,基于Python的“钩子”库,主要用于监听当前电脑上鼠标和键盘的事件。这个库依赖于另一个Python库PyWin32,如同名字所显示的,PyWin32只能运行在Windows平台,所以PyHook也只能运行在Windows平台。pstuil,跨平台地很方便获取和控制系统的进程,以及读取系统的CPU占用内存占用等信息.cement,一个轻量级的、功能齐全的命令行工具click,简单优雅的的命令行接口。clint,Python命令行工具。cliff,创造多层次指令的命令行程序框架。Clime, 可以转换任何模块为多的CLI命令程序,无任何配置。docopt,Python命令行参数分析器。pycli,命令行应用程序,支持的标准命令行解析,测井,单元[测试]和功能测试。Gooey,打开命令行程序,作为为一个完整的GUI应用程序,cookiecutter,命令行工具,从cookiecutters(项目模板)创建项目。例如,Python包项目,jQuery插件项目。percol,为UNIX传统管道pipe命令,添加交互式选择风格。rainbowstream,聪明和漂亮的推特客户终端。Django Models,Django的一部分SQLAlchemy,Python SQL工具包和对象关系映射。peewee,小型的ORM解析器。PonyORM,为ORM提供了一种面向SQL的接口。MongoEngine,Python对象文件映射,使用[MongoDB]。, Django MongoDB引擎MongoDB , Django后台。django-mongodb-engine,Django后台.redisco,一个简单的模型和容器库,使用[Redis]flywheel,Amazon DynamoDB对象映射。butterdb,谷歌电子表格的ORM,Python版。任务与队列celery,芹菜,异步任务队列/工作,基于分布式消息队列。huey,休伊,轻量级,多线程任务队列。mrq,队列先生,分布式任务队列,使用redis & Gevent。rq,简单的工作队列。Queue,Queue模块可以用来实现多线程间通讯,让各个线程共享数据,生产者把货物放到Queue中,供消费者(线程)去使用。simpleq,简单的,可扩展的队列,Amazon SQS基础队列。Psyco,超强的python性能优化工具,psyco 的神奇在于它只需要在代码的入口处调用短短两行代码,性能就能提升 40% 或更多,真可谓是立竿见影!如果你的客户觉得你的程序有点慢,敬请不要急着去优化代码,psyco 或许能让他立即改变看法。psyco 堪称 Python 的 jit。fn.py,Python函数编程:缺失的功能享受FP的实现。funcy,函数编程工具。Toolz,函数编程工具:迭代器、函数,字典。CyToolz,Toolz的Cython实现,高性能的函数编程工具。Ansible,安塞波,极为简单的自动化平台。SaltStack,基础设施的自动化管理系统。Fabric,织物,一个简单,远程执行和部署的语言工具。Fabtools,Fabric的工具函数。cuisine,热门的Fabric的工具函数。psutil,跨平台的过程和系统工具模块。pexpect,控制互动节目。provy,易于使用的配置系统的Python。honcho,Foreman的Python接口,用于管理procfile应用工具。gunnery,多任务执行工具,与网络接口的分布式系统。fig,快速。独立的开发环境中使用泊坞窗。APScheduler,轻量级、但功能强大的在线任务调度程序。django-schedule,Django日程应用程序。doit,任务流道/生成工具。Joblib,Python提供的轻量级的流水线工具函数。Plan,简易生成crontab文件。Spiff,纯Python实现的,功能强大的工作流引擎。schedule,Python作业调度。TaskFlow,有助于使任务执行简单。ctypes,Python标准库,速度更快,Python调用C代码的外部函数接口。cffi,Python调用C代码外部函数接口,类似于ctypes直接在python程序中调用c程序,但是比ctypes更方便不要求编译成so再调用。Cytoolz,python 加速库SWIG,简化封装和接口生成器。Cython,Python优化静态编译器。PyPy,Python解释器的 Python实现。Stackless Python,一个增强版本的Python。它使程序员从基于线程的编程方式中获得好处,并避免传统线程所带来的性能与复杂度问题。Stackless为 Python带来的微线程扩展,是一种低开销、轻量级的便利工具Pyston,使用LLVM和现代JIT技术,对python进行性能优化。pythonlibs,非官方的Windows(32 / 64位)的Python扩展包scapy,优秀的数据包处理库。ino,Arduino命令行工具。Pyro,Python的机器人工具包。pluginbase,一个简单而灵活的Python的插件系统。itsdangerous,数据安全传输工具。blinker,快速Python中的信号/事件调度系统。pychievements,用于创建和跟踪成果框架。python-patterns,Python中的设计模式。pefileWindows PE文件解析器SIP,自动为C和C++库生成Python扩展模块的工具。数据库库名称简介MySQLdb,成熟的[MySQL]数据库模块,Baresql,SQL数据库包ZODB,Python本地对象数据库。一个K-V对象图数据库。pickledb,简单和轻量级的K-V键值存储。TinyDB, 轻量级,面向文档的数据库。mysql-python,MySQL的Python工具库。mysqlclient,mysql-python分支,支持Python 3.,PyMySQL,纯Python写的 MySQL驱动程序,兼容mysql-python。mysql-connector-python,MySQL连接器,来自[Oracle],纯Python编写。oursql,MySQL连接器,提供本地话指令语句和BLOBs支持。psycopg2,最流行的Python PostgreSQL适配器。txpostgres,于Twisted的异步驱动,用于PostgreSQL。queries,psycopg2函数库,用于PostgreSQL。dataset,存储Python字典数据,用于SQLite,MySQL和PostgreSQL。cassandra-python-driver,开源分布式NoSQL数据库系统Apache Cassandra系统的Python驱动.pycassa,简化的cassandra数据库Python驱动。HappyBase,友好的Apache [Hbase]的函数库。PyMongo,MongoDB官方客户端。Plyvel,LevelDB快速和功能丰富的Python接口。redis-py,redis客户端。py2neo,Python客户端(基于Neo4j的RESTful接口).telephus,基于Twisted的cassandra客户端。txRedis,基于Twisted的Redis客户端。网络Curl,Pycurl包是一个libcurl的Python接口,它是由C语言编写的。与urllib相比,它的速度要快很多。Libcurl是一个支持FTP, FTPS, HTTP, HTTPS, GOPHER, TELNET, DICT, FILE 和 LDAP的客户端URL传输库.libcurl也支持HTTPS认证,HTTP POST,HTTP PUT,FTP上传,代理,Cookies,基本身份验证,FTP文件断点继传,HTTP代理通道等等。Requests,用Python语言编写,基于 urllib的开源 HTTP 库。它比 urllib 更加方便,更加 Pythoner。支持 Python3。httpie,命令行HTTP客户端,用户友好的cURL的替换工具。s3cmd,命令行工具,用于管理Amazon S3和CloudFront。youtube-dl,命令行程序,从YouTube下载视频。you-get,Python3写的视频下载工具,可用于YouTube/Youku优酷/Niconico视频下载Coursera,从coursera.org下载视频,可重新命名文件wikiteam,wiki下载工具。subliminal,命令行工具,搜索和下载字幕的函数库。requests,HTTP函数库,更加人性化。grequests,异步HTTP请求+ Gevent(高性能高并发函数库)。urllib3,一个线程安全的HTTP连接池,支持文件post。httplib2,综合HTTP的客户端函数库。treq, Python API接口,Twisted的HTTP客户。Mininet,流行的网络仿真器,API采用python编写。POX,基于Python的开源软件定义网络(SDN)控制开发平台的应用,如OpenFlow的SDN控制器。Pyretic,SDN的编程语言,提供了强大的抽象在网络交换机或仿真器。SDX Platform,基于SDN的IXP实现,利用最小网络,痘和热。inbox.py,Python的SMTP服务器。imbox, Python版本IMAP库。inbox,收件箱,开源邮件工具包。lamson,SMTP服务器。flanker,侧卫,电子邮件地址和MIME解析库。marrow.mailer,高性能可扩展邮件交付框架。django-celery-ses, Django电子邮件后台,使用AWS SES和Celery。modoboa,邮件托管和管理平台,包括现代和简化Web UI。envelopes,邮件工具。mailjet,批量邮寄mailjet API接口,带统计。Talon,利爪,Mailgun库,提取消息和签名。mailjet- Mailjet API implementation for batch mailing, statistics and more., Talon - Mailgun library to extract message quotations and signatures.,pyzmail,编写,发送和解析电子邮件。furl,燃料,小型的的URL解析库库。purl,简单的,干净的API,操纵URL。pyshorteners,纯Python库,URL短网址编辑。short_url,短网址生成。Scrapy,快速屏幕截取和网页抓取的框架。portia,波西亚,Scrapy的可视化扩展。feedparser,信息源解释器RoboBrowser,简单的网页浏览Python函数库,没有使用Web浏览器。MechanicalSoup,网站自动化互动测试工具包。mechanize,网页浏览编程工具。Demiurge,造物主,-PyQuery的轻量级工具。newspaper,提取报纸新闻。html2text,转换HTML为 Markdown格式的文本。python-goose,HTML内容提取器。lassie,莱西,人性化的网站内容检索。micawber,通过UR抓提网页的函数库。sumy,概要,文本和HTML网页的自动文摘模块。Haul,距离,可扩展的图像爬虫。python-readability,可读性工具Arc90,快速的Python接口。opengraph,OpenGraphProtocol协议解析模块,textract,从任何文件,Word,PowerPoint,PDF文件中提取文本,等。sanitize,消毒,使混乱的数据变的理智。AutobahnPython, WebSocket和WAMP的函数库,使用 Twisted和PythonWebSocket-for-Python,websocket客户端和服务器端函数库。SimpleXMLRPCServer,python标准库,简单的XML-RPC服务器,单线程。SimpleJSONRPCServer,JSON-RPC规范实施函数库。zeroRPC,基于ZeroMQ和MessagePack的RPC实现。apache-libcloud,所有云服务的Python接口库。wifi,WiFi -一套个Python库和命令行工具与WiFi,用于[Linux]。streamparse,运行Python代码和数据的实时流。集成了Apache Storm。boto,亚马逊网络服务接口。twython,Twitter推特API。google-api-python-client,谷歌客户端API。gspread,谷歌电子表格的Python API。facebook-sdk,facebook平台Python SDK。facepy,简易的facebook图形APIgmail,Gmail的Python接口。django-wordpress,Django的WordPress的模型和视图。Web框架Django,最流行的Python-Web框架,鼓励快速开发,并遵循MVC设计,开发周期短ActiveGrid企业级的Web2.0解决方案Karrigell简单的Web框架,自身包含了Web服务,py脚本引擎和纯python的数据库PyDBLitewebpy 一个小巧灵活的Web框架,虽然简单但是功能强大CherryPy基于Python的Web应用程序开发框架。Pylons 基于Python的一个极其高效和可靠的Web开发框架Zope 开源的Web应用服务器TurboGears 基于Python的MVC风格的Web应用程序框架Twisted流行的网络编程库,大型Web框架。QuixoteWeb开发框架Flask,轻量级web框架。Bottle,快速,简单和轻量级的WSGI模式Web框架。Pyramid,轻量级,快速,稳定的开源Web框架。web2py,简单易用的全堆栈Web框架和平台。web.py,强大、简单的Web框架。TurboGears,便于扩展的Web框架。CherryPy,极简Python Web框架,支持,HTTP 1.1和WSGI线程池。Grok,基于Zope3的Web框架。Bluebream,开源的Web应用服务器,原名Zope 3。guava,轻量级,高性能的Python-Web框架,采用c语言编写。django-cms,基于Django企业级开源CMS。djedi-cms轻量级但功能强大的Django CMS的插件,内联编辑和性能优化。FeinCMS,基于Django的先进内容管理系统。Kotte,高层次的Python的Web应用框架,基于Pyramid。Mezzanine,强大,一致,灵活的内容管理平台。Opps,基于Django的CMS,用于高流量的报纸、杂志和门户网站。Plone,基于Zope的开源应用服务器Zope。Quokka,灵活,可扩展的,轻量级的CMS系统,使用Flask和MongoDB。Wagtail,Django内容管理系统。Widgy,CMS框架,基于Django。django-oscar,Django奥斯卡,开源的电子商务框架。django-shop,基于Django的网店系统。merchant,支持多种付款处理工具。money,可扩展的货币兑换解决方案。python-currencies,货币显示格式。cornice,Pyramid的REST框架。django-rest-framework,Django框架,强大灵活的工具,可以很容易地构建Web API。django-tastypie,创造精美的Django应用程序API接口。django-formapi,创建JSON API、HMAC认证和Django表单验证。flask-api,提供统一的浏览器体验,基于Django框架。flask-restful,快速构建REST API支持扩展。flask-api-utils,flask的扩展。falcon,猎鹰,高性能的Python框架,构建云API和Web应用程序后端。eve,夏娃,REST API框架,使用Flask,MongoDB和良好意愿。sandman,睡魔,为现有的数据库驱动的系统,自动生成REST API。restless,类似TastyPie的框架。savory-pie,REST API构建函数库(Django,及其他)Jinja2,现代设计师友好的语言模板。Genshi,网络感知输出模板工具包。Mako,马可,Python平台的超高速、轻型模板。Chameleon,变色龙,一个HTML / XML模板引擎。仿照ZPT,优化速度。Spitfire,快速的Python编译模板。django-haystack,大海捞针,Django模块搜索。elasticsearch-py,Elasticsearch官方低级的Python客户端。solrpy,solr客户端。Whoosh,呼,快速,纯Python搜索引擎库。Feedly,建立新闻和通知系统的函数库,使用Cassandra和Redis。django-activity-stream,Django活动流,从你网站上的行动,产生通用的活动流。Beaker,烧杯,一个缓存和会话使用的Web应用程序,独立的Python脚本和应用程序库。dogpile.cache,是Beaker作者的下一代替代作品。HermesCache,Python的缓存库,基于标签的失效及预防Dogpile效果。django-cache-machine,Django缓存机,自动缓存失效,使用ORM。django-cacheops,自动颗粒事件驱动,ORM缓存失效。johnny-cache,约翰尼高速缓存框架,Django应用程序。django-viewlet,渲染模板部件扩展缓存控制。pylibmc,在libmemcached接口。WTForms-JSON,JSON表单数据处理扩展。Deform, HTML表单生成的函数库。django-bootstrap3,bootstrap3,集成了Django。django-crispy-forms,Django程序,可以创建优雅的表单。django-remote-forms,Django的远程表单,Django表格的序列化程序。django-simple-spam-blocker,Django简单的垃圾邮件拦截器。django-simple-captcha,Django简单验证码,简单的和高度可定制的Django应用程序,用于添加验证码图像Ajenti,服务器管理面板。Grappelli,界面花哨的django皮肤。django-suit,Django替代o界面(仅用于非商业用途)。django-xadmin,Django管理面板替代工具。flask-admin,简单的flask管理界面框架flower,实时监控和Web管理面板。Pelican,鹈鹕,Markdown或ReST,字王内容主题。支持 DVCS, Disqus. AGPL。Cactus,仙人掌,设计师的网站静态生成器。Hyde,海德, 基于Jinja2的静态网站生成器。Nikola,尼古拉-一个静态网站和博客生成器。Tags,标签,最简单的静态网站生成器。Tinkerer,工匠,基于Sphinx的静态网站生成器。asyncio,(在Python 3.4 +是Python标准库),异步I/O,事件循环,协同任务。gevent,基于Python的网络库。Twisted,扭曲,事件驱动的网络引擎。Tornado,龙卷风,Web框架和异步网络的函数库。pulsar,脉冲星,事件驱动的并行框架的Python。diesel,柴油,绿色的,基于事件的I/O框架。eventlet,WSGI支持异步框架。pyzmq, 0MQ消息库的Python封装。txZMQ,基于Twisted的0MQ消息库封Crossbar,开源统一应用路由器(WebSocket和WAMP)。wsgiref,Python标准库,WSGI封装实现,单线程。Werkzeug,机床,WSGI工具函数库,很容易地嵌入到你自己的项目框架。paste,粘贴,多线程,稳定的,久经考验的WSGI工具。rocket,火箭,多线程服务,基于Pyramid。netius,快速的、异步WSGI服务器,gunicorn,forked前身,部分用C写的。fapws3,异步网络,用C写的。meinheld,异步WSGI服务器,是用C写的。bjoern,-快速的、异步WSGI服务器,用C写的。认证与安全Permissions函数库,允许或拒绝用户访问数据或函数。django-guardian,Django守护者,管理每个对象的权限,用于Django 1.2 +Carteblanche,管理导航和权限。Authomatic,简单强大的认证/授权客户端。OAuthLib, 通用,规范,OAuth请求签约工具。rauth,用于OAuth 1.0,2.0,的Python库。python-oauth2,利用全面测试,抽象接口来创建OAuth的客户端和服务器。python-social-auth,易于安装的社会认证机制。django-oauth-toolkit,Django OAuth工具包django-oauth2-provider,Django OAuth2工具包。django-allauth,Django认证的应用程序。Flask-OAuthlib,Flask的OAuth工具包sanction,制裁,简单的oauth2客户端。jose,[JavaScript]对象签名和加密(JOSE)草案实施,标记状态。python-jwt,JSON的Web令牌生成和验证模块。pyjwt,JSON的Web令牌草案01。python-jws,JSON的Web令牌草案02。PyCrypto,Python的加密工具包。Paramiko,sshv2协议的实现,提供了客户端和服务器端的功能。cryptography,密码开发工具包。PyNac,网络和密码(NaCl)函数库。hashids,hashids的 Python函数库。Passlib,安全的密码存储/哈希库,非常高的水平。hashlib,md5, sha等hash算法,用来替换md5和sha模块,并使他们的API一致。它由OpenSSL支持,支持如下算法:md5,sha1, sha224, sha256, sha384, sha512.GUI库名称简介PyGtk,基于Python的GUI程序开发GTK+库PyQt用于Python的QT开发库WxPythonPython下的GUI编程框架,其消息机制与MFC的架构相似,入门非常简单,需要快速开发相关的应用可以使用这个TkinterPython下标准的界面编程包,因此不算是第三方库了PySide,跨平台Qt的应用程序和用户界面框架,支撑Qt v4框架。wxPython,混合wxWidgets的C++类库。kivy,创建应用程序GUI函数库,看运行于Windows,Linux,MAC OS X,[Android]和[iOS]。curse,用于创建终端GUI应用程序。urwid,创建终端GUI应用程序窗体的函数库,支持事件,色彩丰富。pyglet,跨平台的窗口和多媒体库的Python。Tkinter,是Python事实上的标准GUI软件包。enaml,创建漂亮的用户界面,语法类似QML。Toga,托加,OS原生GUI工具包。【构建封装】pyenv,简单的Python版本管理。virtualenv,创建独立的Python环境,用于同时安装不同版本的python环境。virtualenvwrapper,是virtualenv的一组扩展。pew,一套管理多个虚拟环境的工具。vex,使运行指定的virtualenv命令。PyRun,一个单文件,无需安装的Python版本管理工具。PIP,Python包和依赖的管理工具。easy_install,软件包管理系统,提供一个标准的分配Python软件和 函式库的格式。是一个附带设置工具的模块,和一个第三方函式库。旨在加快Python函式库的分配程式的速度。类似Ruby语言的RubyGems 。conda,跨平台,二进制软件包管理器。Curdling,一个管理Python包的命令行工具。wheel,Python发行的新标准,旨在替代eggs.cx-Freeze,跨平台的,用于打包成可执行文件的库py2exe, Windows平台的Freeze脚本工具,Py2exe ,将python脚本转换为windows上可以独立运行的可执行程序py2app,MAC OS X平台的Freeze脚本工具。pyinstaller,-转换成独立的可执行文件的Python程序(跨平台)。pynsist,构建Windows安装程序的工具,用Python编写。dh-virtualenv,建立和分发virtualenv(Debian软件包格式)PyPI,新一代的Python包库管理工具。warehouse,新一代的Python包库(PyPI)管理工具。devpi,PyPI服务器和包装/测试/发布工具。localshop,PyPI官方包镜像服务器,支持本地(私人)包上传。buildout,创建,组装和部署应用程序的多个部分,其中一些可能是非基于Python的。SCons,软件构造工具。platformio,一个控制台的工具,构建的代码可用于不同的开发平台。bitbake,特殊设计的工具,用于创建和部署[嵌入式]Linux软件包fabricate,自动为任何编程语言,生成依赖包。django-compressor,Django压缩机,压缩和内联JavaScript或CSS,链接到一个单一的缓存文件。jinja-assets-compressor,金贾压缩机,一个Jinja扩展,通过编译,压缩你的资源。webassets,优化管理,静态资源,独特的缓存清除。fanstatic,球迷,包优化,提供静态文件。fileconveyor,监控资源变化,,可保存到CDN(内容分发网络)和文件系统。django-storages,一组自定义存储Django后台。glue,胶胶,一个简单的命令行工具,生成CSS Sprites。libsass-python,Sass (层叠样式表)的Python接口。Flask-Assets,整合应用程序资源。【代码调试】unittest,Python标准库,单元测试框架。nose,鼻子,unittest延伸产品。pytest,成熟的全功能的Python测试工具。mamba,曼巴,Python的权威测试工具,出自BDD的旗下。contexts,背景,BDD测试框架,基于C#。pyshould,should风格的测试框架,基于PyHamcrest.pyvows,BDD风格测试框架Selenium,web测试框架,Python绑定Selenium。splinter,分裂,测试Web应用程序的开源工具。locust,刺槐,可扩展的用户负载测试工具,用Python写的。sixpack,语言无关的A/B测试框架。mock,模拟对象(英语:mock object,也译作模仿对象),模拟测试库。responses,工具函数,用于mock模拟测试。doublex-强大的测试框架。freezegun,通过时间调整,测试模块。httpretty, HTTP请求的模拟工具。httmock,mock模拟测试。coverage,代码覆盖度量测试。faker,生成模拟测试数据的Python包。mixer,混频器,产生模拟数据,用于Django ORM,SQLAlchemy,Peewee, MongoEngine, Pony ORM等model_mommy,在Django创建测试随机工具。ForgeryPy,易用的模拟数据发生器。radar,雷达,生成随机日期/时间。FuckIt.py,测试Python代码运行。Code Analysispysonar2,Python类型索引。pycallgraph,可视化的流量(调用图)应用程序。code2flow,转换Python和JavaScript代码到流程图。LinterFlake8,源代码模块检查器pylama,Python和JavaScript代码审计工具。Pylint,源代码分析器,它查找编程错误,帮助执行一个代码标准和嗅探一些代码味道。注意:相比于PyChecker,Pylint是一个高阶的Python代码分析工具,它分析Python代码中的错误。Pyflakes,一个用于检查Python源文件错误的简单程序。Pyflakes分析程序并且检查各种错误。它通过解析源文件实现,无需导入。pdb,Python标准库,Python调试器。ipdb,IPython使用的PDB。winpdb,独立于平台的GUI调试器。pudb,全屏,基于python调试控制台。pyringe,-可附着于及注入代码到Python程序的调试器。python-statsd,statsd服务器客户端。memory_profiler, 内存监视。profiling,交互式Python分析器。django-debug-toolbar, Django调试工具栏,显示各种调试信息:当前请求/响应。django-devserver,Django调试工具。flask-debugtoolbar,flask调试工具。